数据转换 (需要更新)¶
数据转换管道的设计¶
遵循典型约定,我们使用 Dataset 和 DataLoader 来加载数据,并使用多个工作进程。 Dataset 返回一个包含数据项的字典,这些数据项对应于模型前向方法的参数。
数据转换管道和数据集是分离的。通常,数据集定义如何处理注释,而数据转换管道定义准备数据字典的所有步骤。管道由一系列数据转换组成。每个操作都接受一个字典作为输入,并输出一个字典供下一个转换使用。
我们在下图中展示了一个经典的管道。蓝色块是管道操作。随着管道的进行,每个操作符可以向结果字典添加新键(标记为绿色)或更新现有键(标记为橙色)。 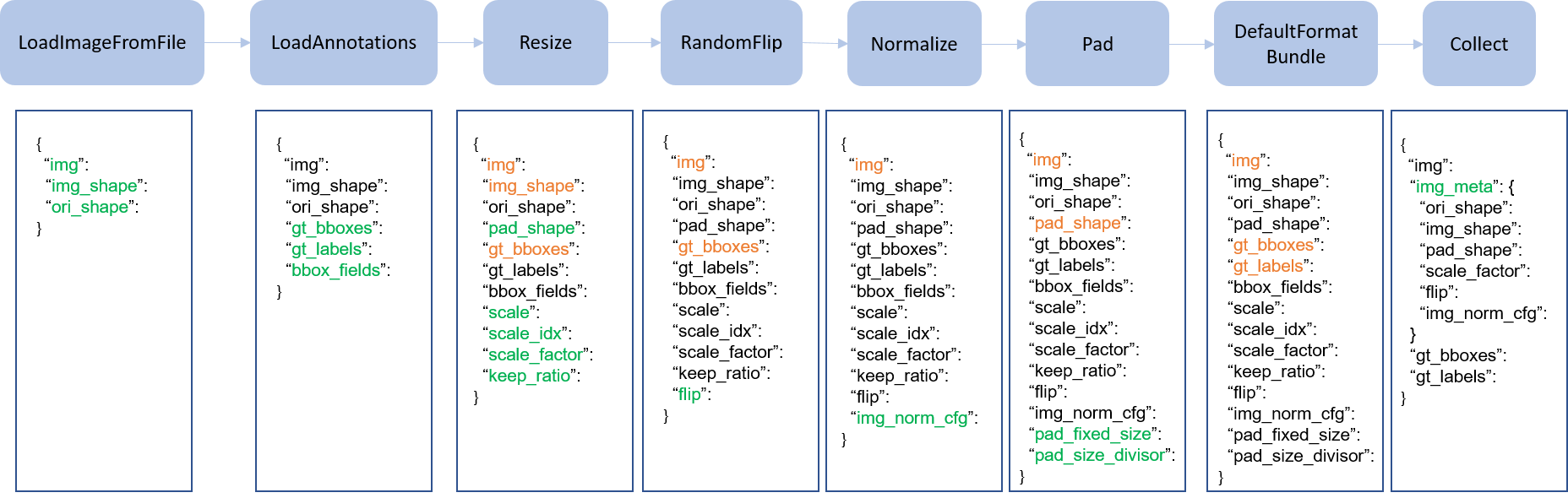
这是一个 Faster R-CNN 的管道示例。
train_pipeline = [ # Training data processing pipeline
dict(type='LoadImageFromFile', backend_args=backend_args), # First pipeline to load images from file path
dict(
type='LoadAnnotations', # Second pipeline to load annotations for current image
with_bbox=True), # Whether to use bounding box, True for detection
dict(
type='Resize', # Pipeline that resize the images and their annotations
scale=(1333, 800), # The largest scale of image
keep_ratio=True # Whether to keep the ratio between height and width
),
dict(
type='RandomFlip', # Augmentation pipeline that flip the images and their annotations
prob=0.5), # The probability to flip
dict(type='PackDetInputs') # Pipeline that formats the annotation data and decides which keys in the data should be packed into data_samples
]
test_pipeline = [ # Testing data processing pipeline
dict(type='LoadImageFromFile', backend_args=backend_args), # First pipeline to load images from file path
dict(type='Resize', scale=(1333, 800), keep_ratio=True), # Pipeline that resize the images
dict(
type='PackDetInputs', # Pipeline that formats the annotation data and decides which keys in the data should be packed into data_samples
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
]